Как заменить все строки в файле, которые начинаются с какого-то префикса
Пример:
1:20 2:25 3:0.432 2:-17 10:12
Я хочу заменить все строки, которые начинаются с , с 2: по 2:0.
Выход:
1:20 2:0 3:0.432 2:0 10:12
5 ответов
Используя sed:
sed -E 's/((^| )2:)[^ ]*/\10/g' in > out
Кроме того, как вдохновлено ответом souravc, если нет шанса a 2: подстрока после запуска строки, не содержащей продвижение 2: подстрока (например, нет шанса a 1:202:25 строка, к которой заменила бы следующая сокращенная команда 1:202:0), команда могла бы быть сокращена к этому:
sed -E 's/2:[^ ]*/2:0/g' in > out
Команда № 1 / разбивка № 2:
-E: делаетsedintepret шаблон как ДО (Расширенное регулярное выражение) шаблон;> out: перенаправленияstdoutкому:out;
sed разбивка команда № 1:
s: утверждает к, выполняет замену/: запускает шаблон(: запускает группу фиксации(: начинает группировать позволенные строки^: соответствует запуску строки|: разделяет вторую позволенную строку: соответствия aсимвол): остановки, группирующие позволенные строки2: соответствия a2символ:: соответствия a:символ): останавливает группу фиксации[^ ]*: соответствия любое количество символов нет/: останавливается шаблон / запускает замещающую строку\1: обратная ссылка заменяется первой группой фиксации0: добавляет a0символ/: останавливается замещающая строка / запускает флаги шаблонаg: утверждает, чтобы выполнить замену глобально, т.е. заменить каждым происшествием шаблона в строке
sed разбивка команда № 2:
s: утверждает к, выполняет замену/: запускает шаблон2: соответствия a2символ:: соответствия a:символ[^ ]*: соответствия любое количество символов нет/: останавливается шаблон / запускает замещающую строку2:0: добавляет a2:0строка/: останавливается замещающая строка / запускает флаги шаблонаg: утверждает, чтобы выполнить замену глобально, т.е. заменить каждым происшествием шаблона в строке
-
1Превосходный, это было точно моей проблемой также. После того, как Debian устанавливают его, переформатировал подкачку, изменяющую UUID. Кажется, что нет никакой опции в установщике, чтобы просто использовать раздел, не форматируя его. – Kris 20 September 2016 в 21:21
Спасибо @kos для sed версия:
Некоторые небольшие модификации для perl путь:
perl -pe 's/((^|\s)2:)[^\s]*/${1}0/g' testdata
Записывают обратно с:
perl -i -pe 's/((^|\s)2:)[^\s]*/${1}0/g' testdata
Объяснение:
((^|\s)2:)[^\s]*
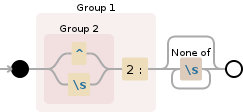
-
1-я Группа фиксации
((^|\s)2:)- 2-я Группа фиксации
(^|\s) -
1-я Альтернатива:
^^утверждают положение в начале строки -
2-я Альтернатива:
\s\sсоответствие любой пробельный символ[\r\n\t\f ]
2:соответствует символам2:буквально - 2-я Группа фиксации
-
[^\s]*, соответствуют отдельному символу, не существующему в списке нижеКвантор:
*Между нулевыми и неограниченными временами, максимально много раз, отдавая по мере необходимости [жадный]\sсоответствие любой пробельный символ[\r\n\t\f ]
Или с Положительный Lookbehind, объяснение @steeldriver
perl -pe 's/(?<=2:)\S*/0/g' testdata
спасибо
(?<=2:)\S*
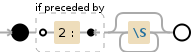
-
(?<=2:)Положительные Lookbehind - Утверждают, что regex ниже может быть подобран2:соответствия символы2: буквально -
\S*соответствие любой цветной Квантор пробела[^\r\n\t\f ]:
*Между нулевыми и неограниченными временами, максимально много раз, отдавая по мере необходимости [жадный]
Этот лайнер с помощью sed
sed -i.bkp 's/2:\([0-9]*\)\|2:\(-\)\([0-9]*\)/2:0/g' input_file
будет в замене строки глобально в input_file, сохраняют файл резервной копии названным input_file.bkp в том же каталоге.
Это может быть, далее сокращают использование, которое расширенный regexes как предложил Косом, как
sed -ri.bkp 's/2:\-?[0-9]*/2:0/g' input_file
-
1
Я использовал бы основное awk цикл:
$ awk '{for (i=1; i<=NF; i++) $i~/^2:/ && $i="2:0"}1' file
1:20 2:0 3:0.432 2:0 10:12
Это циклично выполняется через все поля. Каждый раз, когда один из них запускает с 2:, он заменяет все это 2:0. Наконец, эти 1 обозначает Правда, так, чтобы вся строка была распечатана.
-
1
echoбыла бы лучшая команда для добавления.catпредназначен для конкатенации файлов. – J. Starnes 15 January 2018 в 16:21
Используя python:
#!/usr/bin/env python2
import re
with open('test_dir/unix_se.txt') as f:
for line in f:
print re.sub(r'(?:(?<=(?: 2:))|(?<=(?:^2:)))[^ ]*', '0', line).rstrip()
Здесь мы имущие, используемые re.sub функция re модуль.
re.sub()имеет шаблонsub(pattern, repl, string, count=0, flags=0)Поскольку мы не будем использовать значения в группе далее, мы использовали нотацию негруппы фиксации
(?:)(?:(?<=(?: 2:))|(?<=(?:^2:)))использует положительную нулевую ширину, оглядываются для соответствия2:в запуске или сопровождаемый пространством.[^ ]*будет соответствовать нулю или большему количеству символов перед пространством, после2:и затем замените их0.
Вот пример:
Вход:
2:456 1:20 2:25 3:0.432 2:-17 10:12
1:20 2:25 3:0.432 2:-17 10:12 2:543 2:-78
Вывод:
2:0 1:20 2:0 3:0.432 2:0 10:12
1:20 2:0 3:0.432 2:0 10:12 2:0 2:0
-
1Спасибо. Я didn' t думают, что драйверы окон работали бы над Linux. – hislittlecuzin 12 August 2016 в 13:28